Students Shine in Successful Poster Presentation Session
In a focused showcase of statistical research, the Department hosted a Poster Presentation Session on Friday, December, 1, 2023, featuring presentations from 10 students in our PhD Program. Faculty, staff, emeritus faculty, and friends of the department gathered to engage in discussions over coffee, bagels, and cream cheese and enjoy the showcased posters.
Below provides details regarding each student’s presented research; accompanying each image are the respective abstracts, providing an overview of the key aspects of their work.
Jimmy Hickey

Abstract: Transfer learning uses a data model, trained to make predictions or inferences on data from one population, to make reliable predictions or inferences on data from another population. We develop a statistical framework for model predictions based on transfer learning, called RECaST, which provides uncertainty quantification for predictions, which is mostly absent in the literature. We mathematically and empirically demonstrate the validity of our RECaST approach for transfer learning between linear models, in the sense that prediction sets will achieve their nominal stated coverage, and we numerically illustrate the method’s robustness to asymptotic approximations for nonlinear models.
Yi Liu
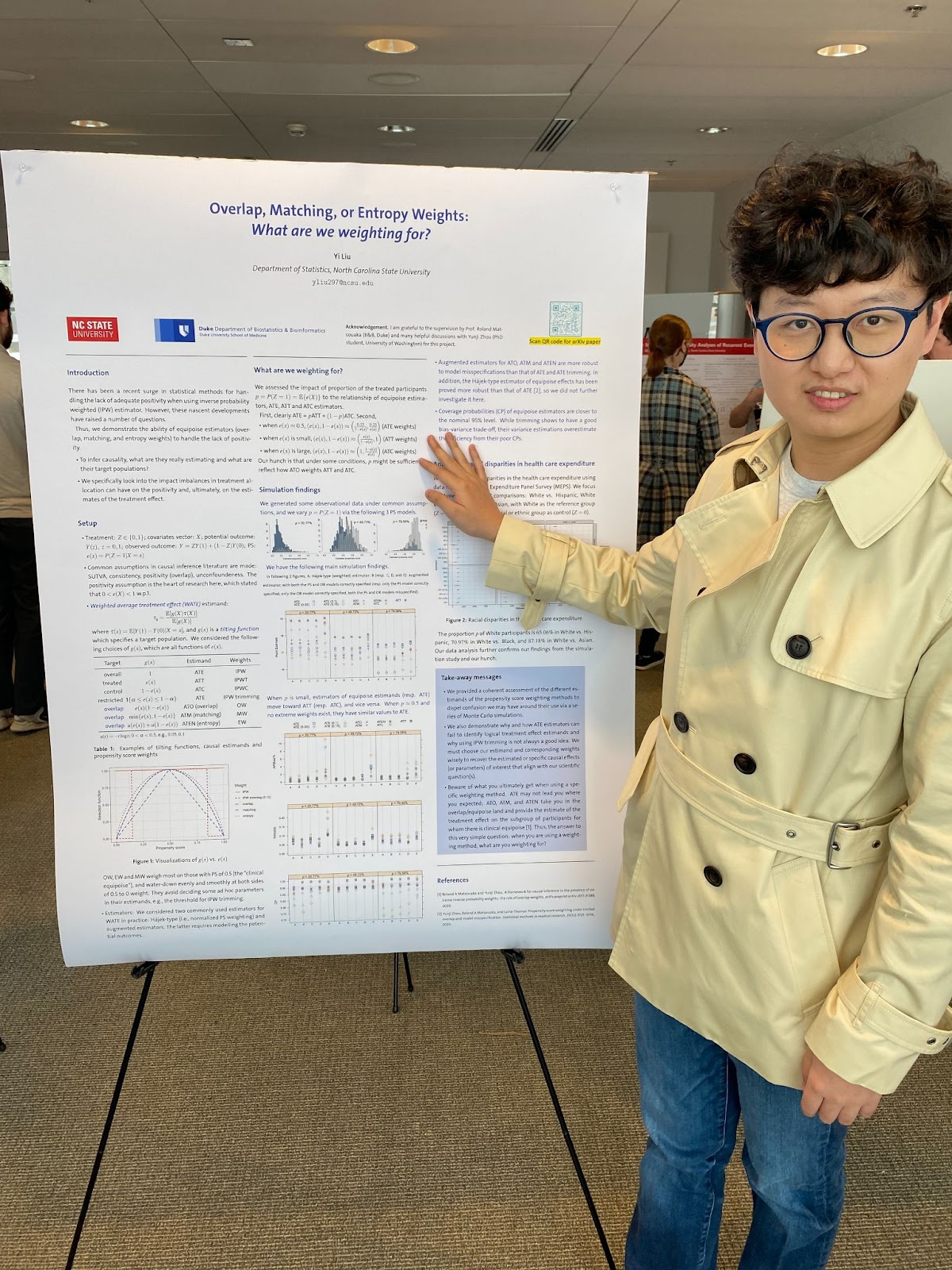
Abstract: There has been a recent surge in statistical methods for handling the lack of adequate positivity when using inverse probability weights (IPW). However, these nascent developments have raised a number of questions. Thus, we demonstrate the ability of equipoise estimators (overlap, matching, and entropy weights) to handle the lack of positivity. Compared to IPW, the equipoise estimators have been shown to be flexible and easy to interpret. However, promoting their wide use requires that researchers know clearly why, when to apply them, and what to expect. In this work, we provide the rationale to use these estimators to achieve robust results. We specifically look into the impact imbalances in treatment allocation can have on the positivity and, ultimately, on the estimates of the treatment effect. We zero into the typical pitfalls of the IPW estimator and its relationship with the estimators of the average treatment effect on the treated (ATT) and on the controls (ATC). Furthermore, we also compare IPW trimming to the equipoise estimators. We focus particularly on two key points: What fundamentally distinguishes their estimands? When should we expect similar results? Our findings are illustrated through Monte-Carlo simulation studies and a data example on healthcare expenditure.
Siyi Liu
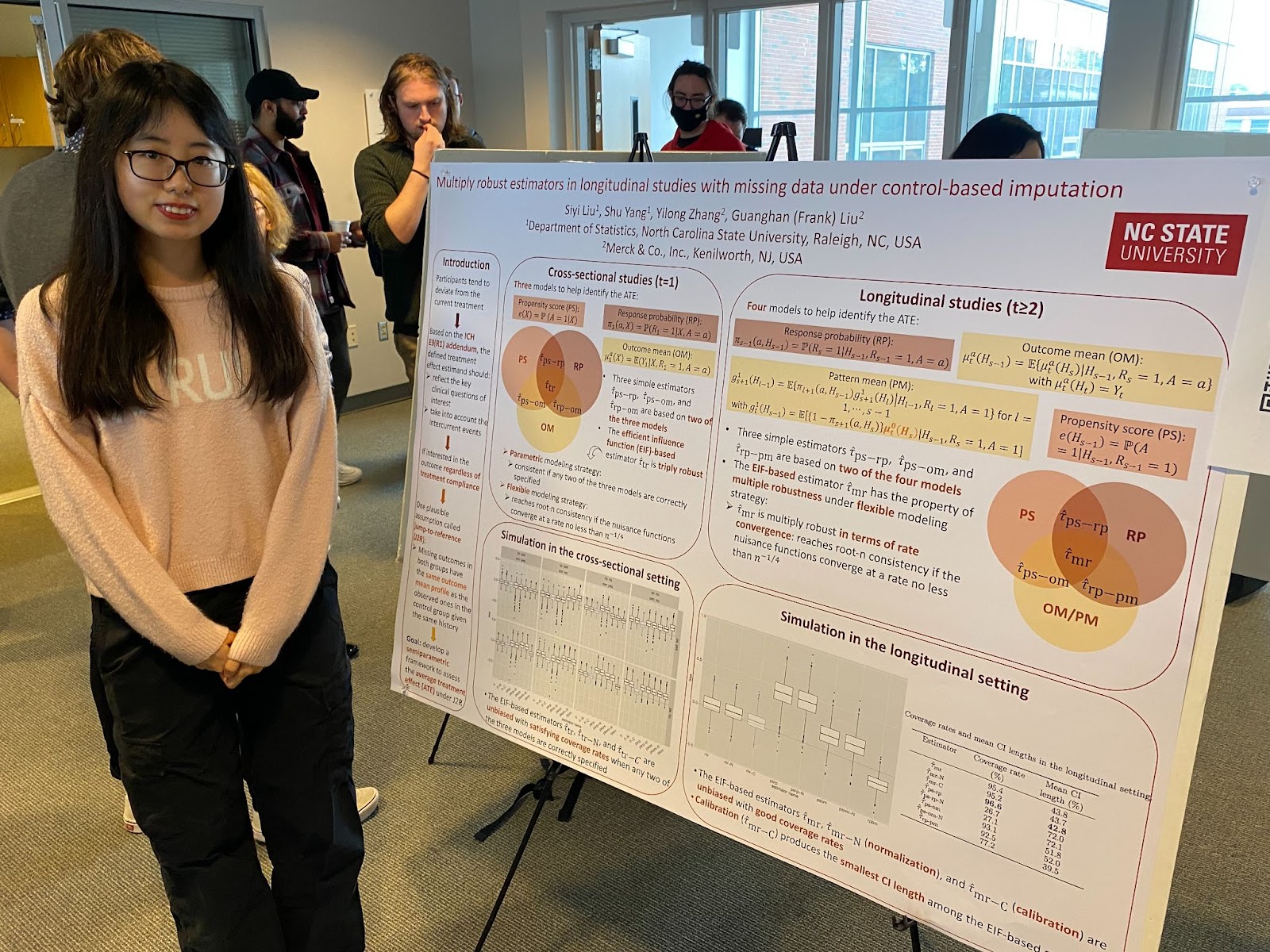
Abstract: Longitudinal studies are often subject to missing data. The recent guidance from regulatory agencies such as the ICH E9(R1) addendum addresses the importance of defining a treatment effect estimand with the consideration of intercurrent events. Jump-to-reference (J2R) is one classical control-based scenario for the treatment effect evaluation, where the participants in the treatment group after intercurrent events are assumed to have the same disease progress as those with identical covariates in the control group. We establish new estimators to assess the average treatment effect based on a proposed potential outcomes framework under J2R. Various identification formulas are constructed, motivating estimators that rely on different parts of the observed data distribution. Moreover, we obtain a novel estimator inspired by the efficient influence function, with multiple robustness in the sense that it achieves root n-consistency if any pairs of multiple nuisance functions are correctly specified, or if the nuisance functions converge at a slower rate when using flexible modeling approaches. The finite-sample performance of the proposed estimators is validated in simulation studies and an antidepressant clinical trial.
Xinyu Zhang
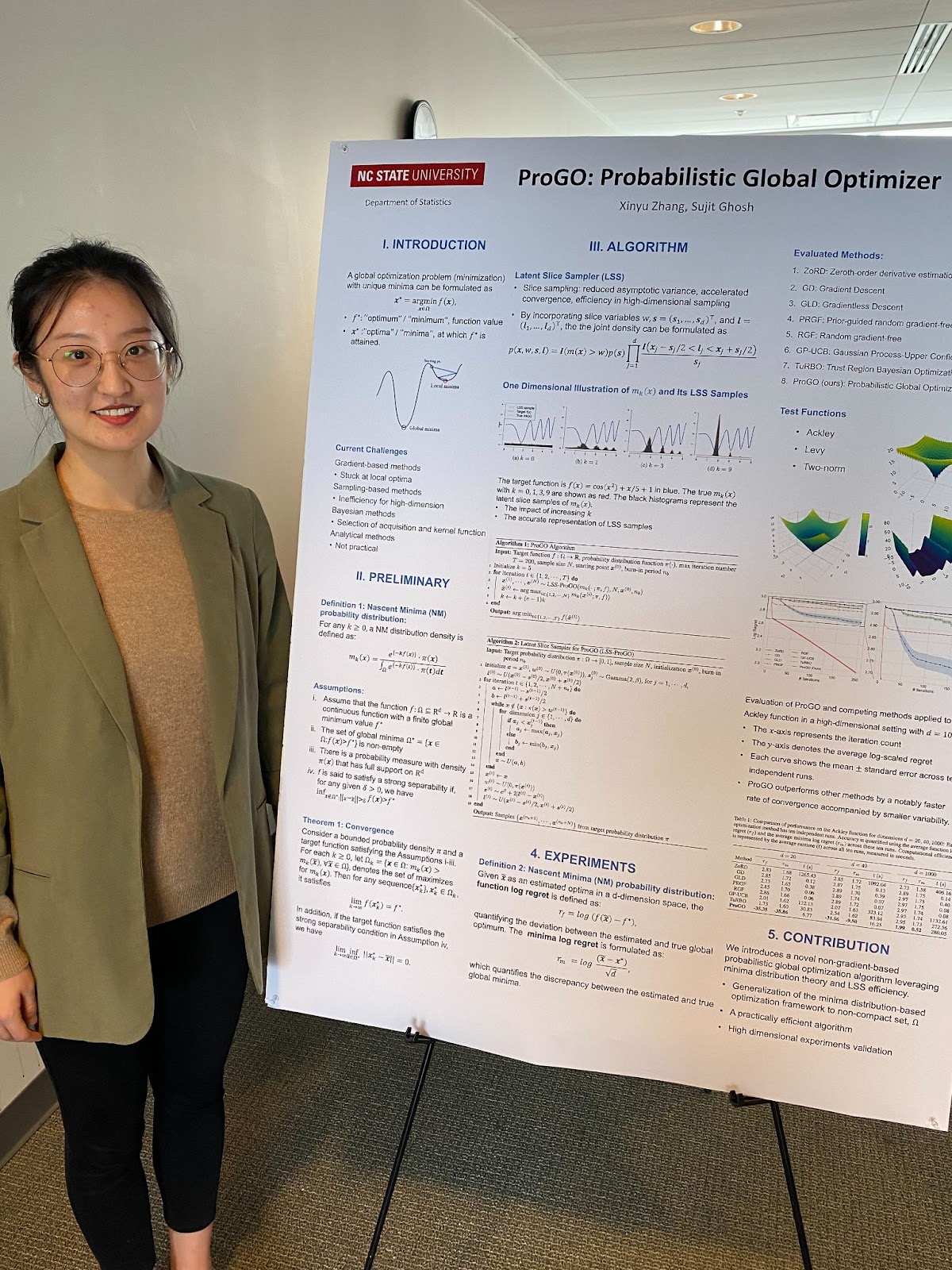
Abstract: In the field of global optimization, many existing algorithms face challenges posed by non-convex target functions and high computational complexity or unavailability of gradient information. These limitations, exacerbated by sensitivity to initial conditions, often lead to suboptimal solutions or failed convergence. This is true even for Metaheuristic algorithms designed to amalgamate different optimization techniques to improve their efficiency and robustness. To address these challenges, we develop a sequence of multidimensional integration-based methods that we show to converge to the global optima under some mild regularity conditions. Our probabilistic approach does not require the use of gradients and is underpinned by a mathematically rigorous convergence framework anchored in the nuanced properties of nascent optima distribution. In order to alleviate the problem of multidimensional integration, we develop a latent slice sampler that enjoys a geometric rate of convergence in generating samples from the nascent optima distribution, which is used to approximate the global optima. The proposed Probabilistic Global Optimizer (ProGO) provides a scalable unified framework to approximate the global optima of any continuous function defined on a domain of arbitrary dimension. Empirical illustrations of ProGO across a variety of popular non-convex test functions (having finite global optima) reveal that the proposed algorithm outperforms, by order of magnitude, many existing state-of-the-art methods, including gradient-based, zeroth-order gradient-free, and some Bayesian Optimization methods, in term regret value and speed of convergence. It is, however, to be noted that our approach may not be suitable for functions that are expensive to compute.
Charlie Song

Abstract: Dynamic functional concurrent regression model predicts future subject-specific trajectories based on historical outcomes as well as functional predictors measured concurrently with the outcomes. Typically, the observation and censoring times are assumed to be independent of the longitudinal outcome, which may be violated in the practice. Methods that fail to account for informative censoring can lead to inaccurate predictions. An adaptive subject-specific (aSUJB) weighting method is proposed. Both the mean function and covariance function can be estimated consistently using the proposed method with penalized spline under the functional concurrent regression model framework. Simulation and real data application are provided to demonstrate the proposed method.
Sarah Fairfax

Abstract: Longitudinal clinical trials for which recurrent events are of interest are commonly subject to missing event data. Primary analyses in such trials are typically performed assuming events are missing at random, a typically unverifiable assumption in practice. Sensitivity analyses are necessary to assess robustness of primary analysis conclusions to missing data assumptions. Control-based imputation is an attractive approach in superiority trials for imposing conservative assumptions on how data may be missing not at random. A popular approach to implementing control-based assumptions for recurrent events is multiple imputation (MI), but Rubin’s variance estimator is often biased for the true sampling variability of the point estimator in this setting. We propose distributional imputation (DI) with corresponding wild bootstrap variance estimation procedure for control-based sensitivity analyses of recurrent events. In simulations, DI produced more reasonable standard error estimates than the standard MI under control-based imputation of recurrent events.
Matthew Singer

Abstract: Among medical professionals, it is well known that patients often do not accurately report their symptoms. Incorrect or incomplete understanding of patient symptoms is rampant throughout all areas of study, and the problem of identifying and correcting incorrect patient reports of symptoms has been studied thoroughly. Previously, other researchers have attempted to remedy this problem through manual review, complex imputation systems, Semi-Supervised Autoencoders, and Convolutional Networks. In this paper, we show how vector representations of symptoms can be achieved through NLP embedding systems, introduce the masked symptom problem, and introduce the symptom recognition problem. We demonstrate how each word embedding technique, when utilized with conformal prediction, can produce valid, efficient prediction sets for both symptom recognition and missing symptom prediction within patient reports. Our experiments found that models using our constructed symptom embeddings perform sufficiently compared to the full-information model and other state-of-the-art medical embeddings.
Hyoshin Kim
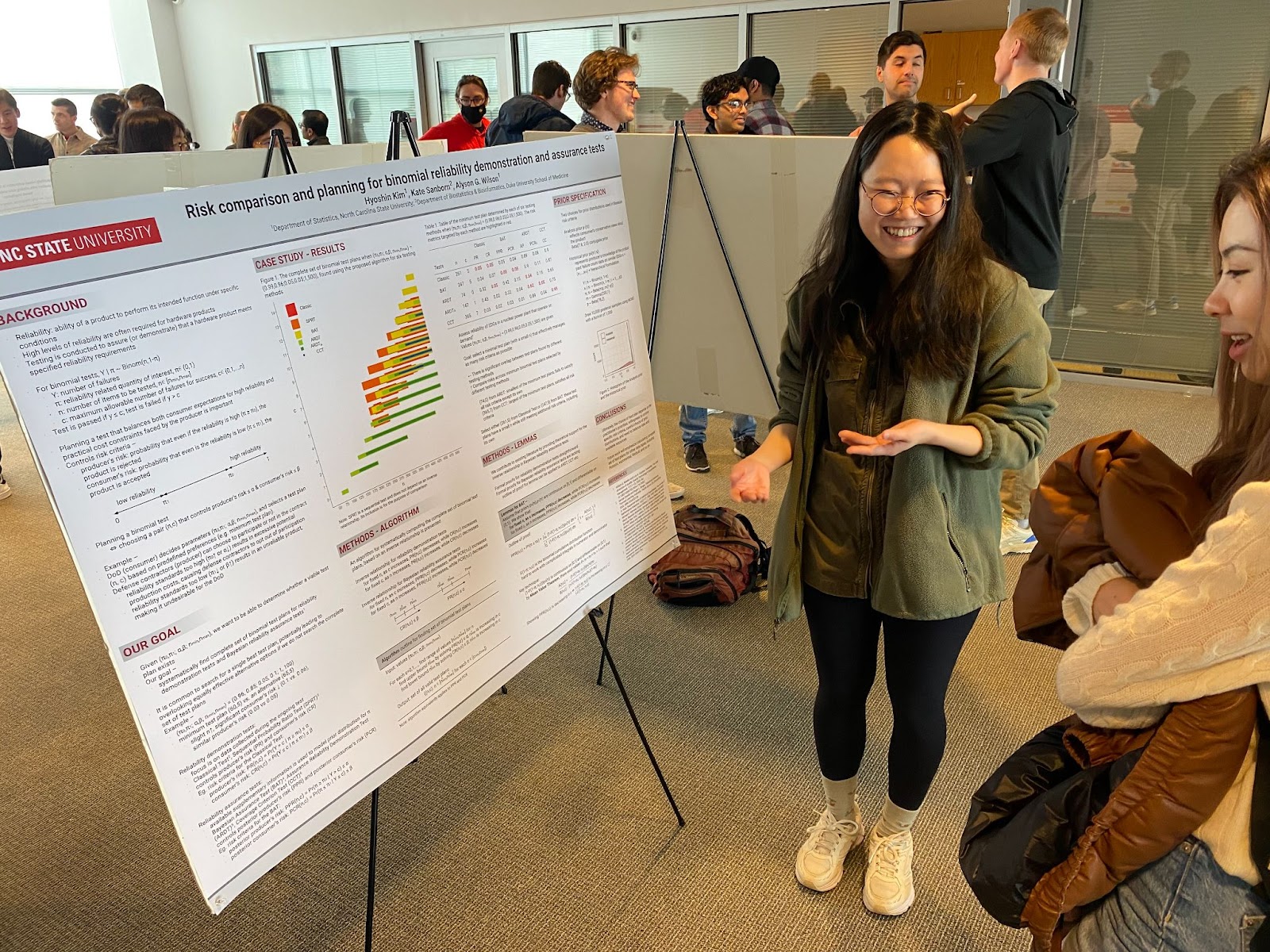
Abstract:
Achieving a balance between the (posterior) consumer’s risk and the (posterior) producer’s risk is crucial when planning demonstration tests. Instead of focusing on finding a single best test plan, we introduce a general framework to systematically identify the complete set of binomial test plans by leveraging the inverse relationship between the two risks. The framework is applied to well-known demonstration tests, encompassing reliability demonstration tests and Bayesian reliability assurance tests. Efficient algorithms are presented to compute the set of test plans, providing practitioners with a comprehensive range of options to choose from. This work also contributes to the existing literature by providing formal proofs for the inverse relationship in Bayesian reliability assurance tests. A case study is presented to illustrate the framework’s application and compare the risks associated with different test plans.
Matthew Shisler
Abstract: Plant phenology is the study of seasonal plant life developmental stages used by scientists and policymakers to understand agricultural management practices, climate change effects and ecosystem processes. In particular, land surface phenology relates to the seasonal pattern of variation in vegetated land surfaces where measurements are typically collected via remote sensing. In the past, statistical estimates of plant phenometrics required a substantial amount of data, sometimes aggregated over many years or pixels from satellite imagery. Recent work has drawn on the power of Bayesian hierarchical modeling applied pixel-wise to reliably quantify complete annual sequences of phenometrics despite sparse time-series data. Our project extends this work by jointly modeling phenology across pixels to account for spatial dependencies. We also employ a basis-function approximation technique to reduce computational cost. The model is applied to USGS/NASA Landsat satellite data collected from 1985 to 2019.
Nate Wiecha

Abstract: Background: Several statistical methods for analyzing chemical mixtures require effects of exposures in the same direction (directional homogeneity). We use data from the GenX Study of PFAS (Per- and polyfluoroalkyl substances) exposure in North Carolina to evaluate existing methods when this assumption is unmet. Methods: We used data from 367 women enrolled in the GenX Study. Exposures were serum concentrations of PFAS: PFHpS, PFHxS, PFNA, PFOA, and PFOS (correlations 0.5–0.8). Outcomes were serum concentrations of thyroid hormones: Free T4 (FT4), Total T4 (TT4), and Thyroid Stimulating Hormone (TSH). Methods considered were linear regression, quantile regression, weighted quantile sum (WQS) regression, quantile g-computation (QGC), Bayesian kernel machine regression (BKMR), and generalized additive models (GAMs) estimated using Bayesian or frequentist methods. We evaluated their assumptions’ appropriateness; transparency; and performance on simulated data. Results: For the analysis, we selected GAMs, which model joint nonlinear relationships, are transparent, and have relatively good hypothesis tests. Linear regression requires specifying nonlinearities manually. Without directional homogeneity, WQS cannot be used and QGC’s performance is compromised. BKMR is flexible but less transparent. Conclusion: GAMs are the most appropriate existing method to analyze PFAS’ association with health outcomes without directional homogeneity.
- Categories: